一、项目框架

二、算法分类
1、数据加密算法
MD5加密
MD5加密是一种不可逆的加密算法,加密过程中不需要使用密钥,输入明文后由系统直接经过加密算法处理成密文,这种加密后的数据是无法被解密的,只有重新输入明文,并再次经过同样不可逆的加密算法处理,得到相同的加密密文并被系统重新识别后,才能真正解密。
在本平台中,MD5加密主要用于加密数据集中的主键,加密后的主键既可以用来串联各个数据表,又不会泄露隐私信息。
2、数据匿名算法
-
攻击场景
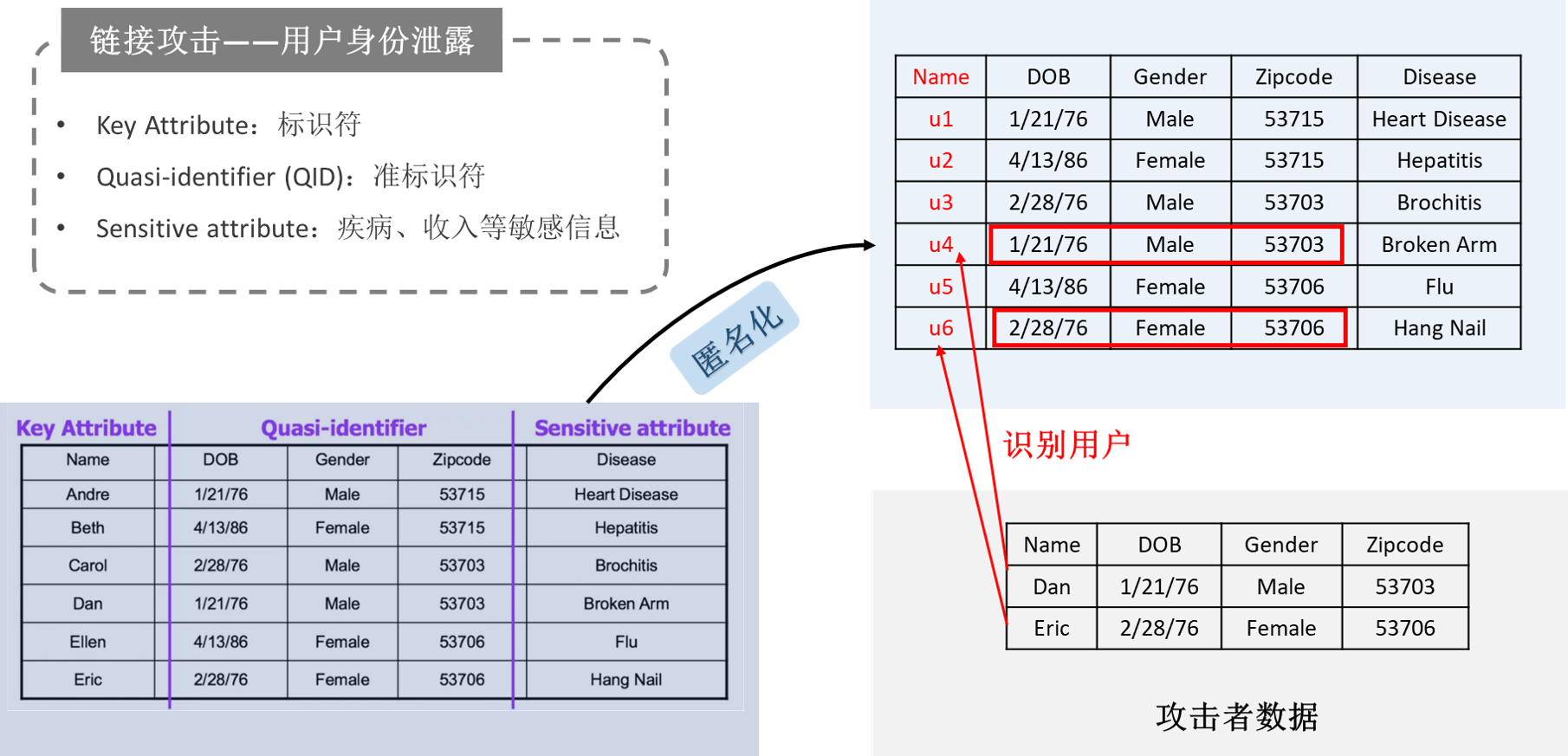
-
① K-匿名(k-anonymity)
k-anonymity是匿名化数据的一种性质。如果一组公开的数据中,任何一个人的信息都不能和其他至少k-1人区分开,则称该数据满足k-anonymity,该组数据称为一个等价类(An equivalence class)。k-匿名性的提出是为了解决如下问题:“给定一组结构化的具体到个人的数据,能否给出一组经过处理的数据,使我们可以证明数据中涉及的个人不能被再识别,同时还要保证数据仍具有使用价值。”使一组数据满足k-anonymity的过程称为k-anonymization。
我们利用数据抑制以及数据泛化1等方法对结构化数据中个人的属性进行处理,使得表中任何一个人的信息都不能和其他至少K-1个人区分开,即实现每个人都不能被再识别的“匿名化”效果。

-
② L-多样性(l-diversity)
如果一个等价类至少有l个敏感属性的“良好表示”(well-represented)值,则称该等价类具有l多样性。如果一个表中的所有等价类都有l多样性,则称该表具有l多样性。
为了填补K-匿名性算法无法应对的同质性攻击和背景知识攻击漏洞,我们引入L-多样性算法2,确保每个K-匿名组中至少包含L个不同的敏感属性值,或者说使得每一个等价类都至少拥有L个敏感属性的“良好表示”值。我们基于多种“良好表示”衡量指标(可区分多样性、熵多样性、递归多样性)实现L-多样性,并从中选出最优算法。
-
③ T-相近性(t-closeness)
若一个等价类的敏感属性取值分布与整张表中该敏感属性的取值分布的距离不超过阈值t,则称该等价类具有t相近性。若一个表中所有等价类都有t相近性,则该表也有t相近性。
为了防御L-多样性无法应对的偏斜攻击和相似性攻击,我们引入T-相近性算法3,在考虑敏感属性值的分布的基础上通过降低数据表示的粒度来保护数据集中的隐私,使每个等价类的敏感属性取值分布与整张表中敏感属性取值分布距离不超过阈值T。我们基于多种分布距离度量指标实现T-相近性并从中选出最优算法。
3、具有理论隐私保障的隐私保护机制
-
差分隐私(Differential Privacy)
- 基本思想:差分隐私的设计初衷是为了防御差分攻击,即攻击者根据某个个体是否在整体中出现时算法输出的差别,来推测隐私相关信息。因此,差分隐私的目的就是要保证任何一个个体是否在整体中出现时,对于算法的输出的影响是微乎其微的,从而达到隐私保护的目的。
- 具体实现:向原数据中加入能够满足差分隐私机制的噪声4。
4、针对基于机器学习的隐私属性推断攻击的防御算法
-
攻击场景
数据持有者将公开的数据(X)进行发布或共享给第三方,此时,恶意的数据使用者可能借助机器学习算法,基于公开数据(X)与隐私属性(Y)之间的潜在联系,建立机器学习推断攻击模型,从而基于发布的X实现对Y的准确推测。为了防御这种攻击,我们在DataGuard框架中实现了三种防御算法。
-
① 混淆(Obfuscation)
- 基本思想:在公开数据(X)发布之前对其进行混淆,并发布混淆后的公开数据(X'),从而模糊X与Y之间的潜在关联关系,使得机器学习推断攻击模型无法根据所发布的混淆公开数据(X')准确推断隐私属性Y。
- 具体实现:PrivCheck(Ubicomp 2016)5使用互信息来衡量发布数据X'与隐私属性Y之间的相关性(即隐私泄露量),使用了X与X'之前的距离来衡量与控制数据效用损失。该问题被建模为在给定的数据效用损失限制条件下,求解一个最优的混淆函数来最小化隐私泄露量。它是一个凸优化问题,可采用凸优化求解器进行求解。
-
② 对抗样本(Adversarial Examples)
- 基本思想:对公开数据中的每个样本加入精心设计的噪声,使其转化为针对机器学习推断攻击模型的对抗样本,以逃避攻击(evasion attack)的思想来防御攻击模型的推测攻击。
- 具体实现:AttriGuard(USENIX 2018)6利用逃避攻击的思想,为每个数据样本求解一个最小的“噪声量”。当数据样本上加入该噪声后,对样本本身的数据效用水平影响是有限的,但能够有效地降低推测攻击模型针对隐私属性的推测精度。
-
③ 对抗训练(Adversarial Training)
- 基本思想:利用对抗训练方法训练一个特征提取器,将原数据样本转化为低维向量表示,该向量表示保留了原数据样本X的大部分信息的同时,剔除了与隐私属性Y相关的信息。
- 具体实现:TIPRDC(KDD 2020)7通过互信息衡量了原数据样本与低维向量表示之间的相关性,以及隐私属性与低维向量之间的相关性。该方法提供了一个框架,目的是训练一个特征提取器将原数据样本转化为低维向量表示,该特征提取器能够最大化原数据样本与低维向量表示之间的互信息,同时最小化低维向量表示与隐私属性之间的互信息。它通过对抗训练的方式来训练该特征提取器达到以上的隐私保护目的。
三、评价指标
1、效用指标
- GIL(generalized information loss,泛化信息损失)7通过量化已泛化的域值的比例,捕获泛化特定属性时产生的损失。 GIL越小,表示效用损失越少。
- DM(discernibility metric,分辨力指标)7通过给每个记录分配一个惩罚值,来衡量一个记录与其他记录的不可区分程度,惩罚值等于它所属的等价类的大小。DM越小,表示效用损失越少。
- CAVG(average equivalence class size metric,平均等价类指标)测量等价组的创建是否接近最佳情况。CAVG越小,表示效用损失越少。
- dist(distance,距离)衡量原始数据集和新数据集的平均欧式距离。dist越接小,表示效用损失越少。
- acc(downstream prediction task accuracy,下游预测任务准确率)基于隐私处理后的数据集训练下游任务的机器学习模型,计算下游任务分类准确率(此指标的计算需指定效用属性)。acc越高,表示效用损失越少。
2、风险指标
- Ra(lowest prosecutor risk,最低检察官风险)8刻画重识别概率大于0.2的数据记录占总体的比例,Ra越小,表示风险越低。
- Rb(highest prosecutor risk,最高检察官风险)8刻画数据集中最大的重识别概率,Rb越小,表示风险越低。
- Rc(average prosecutor risk ,平均检察官风险)8刻画平均重识别概率,Rc越小,表示风险越低。
- low(records affected by lowest risk,最低风险影响的记录数)8是达到最低风险的记录占总体的比例,在Rc较低的情况下low越大,表示风险越低。
- high(records affected by highest risk,最高风险影响的记录数)8是达到最高风险的记录占总体的比例,在Rc较低的情况下high越小,表示风险越低。
- uni(sample uniques,唯一样本)是等价组大小为1的记录数量占总体的比例,uni越小,表示风险越低。
- priv(private attribute inference attack accuracy,隐私属性推断攻击准确率)模拟攻击者的角色,基于隐私处理后的数据集训练隐私属性预测的机器学习模型,计算隐私属性推断的准确率。priv越低,表示风险越低。
3、权衡指标
- tradeoff(trade-off between utility and risk,风险与效用权衡指标)定义为:(1)对于数据匿名算法:效用指标GIL和风险指标Rb的乘积;(2)对于指定效用属性的其他算法:隐私指标priv乘以效用指标acc下降的值;(3)对于未指定效用属性的其他算法:隐私指标priv乘以效用指标dist。tradeoff越小,表示风险越低,同时效用损失越小。我们基于tradeoff指标自动为用户推荐合适的参数取值。
参考文献
- Samarati P, Sweeney L. Protecting Privacy when Disclosing Information: k-Anonymity and Its Enforcement through Generalization and Suppression[J].
- Machanavajjhala A, Kifer D, Gehrke J, Venkitasubramaniam M. L -diversity: Privacy beyond k -anonymity[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): 3.
- Li N, Li T, Venkatasubramanian S, Labs T. t-Closeness: Privacy Beyond k-Anonymity and -Diversity[J].
- Abadi M, Chu A, Goodfellow I, McMahan H B, Mironov I, Talwar K, Zhang L. Deep Learning with Differential Privacy[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security.
- Yang D, Zhang D, Qu B, Cudré-Mauroux P. PrivCheck: privacy-preserving check-in data publishing for personalized location based services[C]//Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing. New York, NY, USA:Association for Computing Machinery,2016: 545–556.
- Jia J, Gong N Z. Attriguard: a practical defense against attribute inference attacks via adversarial machine learning[C]//Proceedings of the 27th USENIX Conference on Security Symposium. USA:USENIX Association,2018: 513–529.
- Li A, Duan Y, Yang H, Chen Y, Yang J. TIPRDC: Task-Independent Privacy-Respecting Data Crowdsourcing Framework for Deep Learning with Anonymized Intermediate Representations[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Virtual Event CA USA:ACM,2020: 824–832.
- Ayala-Rivera V, McDonagh P, Cerqueus T, Murphy L. A Systematic Comparison and Evaluation of k-Anonymization Algorithms for Practitioners[J]. 2014.
- Emam K E. Guide to the De-Identification of Personal Health Information[M]. New York:Auerbach Publications,2013.